

Welcome to an insightful journey that explores the fascinating realm of large language models (LLMs).
In recent years, AI has not just permeated various aspects of our lives; it has become a driving force, reshaping industries and redefining how we interact with technology. Among the most remarkable of these developments is the emergence of tools like ChatGPT or Claude, which hold the potential to transform particularly the legal sector.
In this post we will provide you with a solid understanding of LLMs—their capabilities, ethical considerations, and potential applications. Whether you’re new to AI or seeking to deepen your knowledge, this guide is designed to equip you with a clear comprehension of what LLMs are and why they matter.
WHAT IS AN LLM?
Large Language Models, or LLMs, are a fascinating subset of artificial intelligence, specifically designed as neural networks that thrive on understanding and generating human language. To grasp the significance of LLMs, let’s start with neural networks: This term covers algorithms designed to recognize underlying patterns in data, closely mimicking the function of biological neurons and ultimately the human brain. In essence, neural networks are the scaffolding of AI that enables it to learn and adapt.
Now, LLMs are trained on a vast scale, absorbing every piece of text they can access—from books to websites, and everything in between. This training involves not just mere data ingestion but an intricate process of learning the nuances of natural language. By sifting through millions of documents, LLMs learn to understand context, domain-specific vocabulary, language patterns, even humor and irony, and the complex web of human written communications.
The Evolution from Traditional Programming to AI
Traditional programming relies on explicit instructions: A developer writes code that specifies every action the system needs to take. It’s a deterministic process where if ‘X’ happens, then ‘Y’ must follow. This method works well for straightforward, predictable tasks but falls short in handling the ambiguity and fluidity inherent in human language.
In contrast, LLMs operate under a paradigm where the model learns from examples rather than following hard-coded rules. This is analogous to teaching a child through stories and examples rather than giving them a strict set of instructions. For instance, in image recognition, traditional programming would require defining every possible variation of each letter of the alphabet. But with LLMs, the model is instead exposed to a diverse array of handwritten letters, enabling it to predict and recognize new letters based on its learned patterns.
Why LLMs are Revolutionary
ChatGPT, the popular LLM developed by OpenAI, and other LLMs exemplify this new era as they can generate text, answer questions, summarize lengthy documents, and even write creative content, adapting to new data inputs dynamically. This adaptability is what sets LLMs apart—rather than being confined to pre-programmed responses, they learn and evolve with each interaction.
Moreover, the potential of LLMs to improve is exponential (pdf). As more and more data is published in the internet, and as these models generate and and also learn from synthetic data (data created by other models), their capabilities will enhance. This means that what we see today is merely the starting point; these models are set to become more sophisticated, more intuitive, more helpful, and more disruptive. They are currently at their most primitive stage and will only advance from here.
HISTORY OF AI/ML
To appreciate the capabilities and impact of today’s LLMs, it’s essential to understand where they come from.
From Early Beginnings to Neural Networks
The inception of language models can be traced back to 1966 with the introduction of Eliza, the first language model (video). Eliza was groundbreaking for its time, using a script to mimic conversation by matching user inputs to pre-programmed responses based on keywords. However, its simplicity meant that it couldn’t sustain the illusion of understanding for long, as repetitive interactions exposed its limitations.
The development of AI then entered a dormant phase, where progress was slow. Notably, it wasn’t until 1972 that recurrent neural networks (RNN) were capable of learning. These networks were the predecessors to modern AI, using layers and weights to predict the next word in a sentence—a stark contrast to the rigid, rule-based programming of earlier models.
The Advent of Deep Learning and Transformers
The early 2000s saw the rise of deep learning, which developed until a pivotal moment in 2017. This is when Google DeepMind introduced the world to the concept of Transformers with their seminal paper, “Attention is All You Need” This breakthrough introduced a new architecture that dramatically improved the efficiency of training models and enabled more complex understanding and generation of human language.
Transformers utilize mechanisms like self-attention to process words in relation to all other words in a sentence, unlike earlier models that processed words in isolation. This capability significantly enhanced the model’s understanding of context.
Breakthroughs in LLMs: From GPT to BERT and Beyond
Following the development of Transformers, OpenAI released GPT-1 in 2018, a model with 117 million parameters that set new standards for text generation (paper). Shortly thereafter, BERT (Bidirectional Encoder Representations from Transformers) was released by Google. BERT’s bidirectionality, allowing it to consider context prior and after the position of a word in a text (called left and right context, respectively), marked a significant advancement over unidirectional models.
The scale and capability of LLMs continued to grow, with OpenAI’s GPT-2 launching in early 2019 with 2.5 billion parameters (paper), followed by GPT-3 in June 2020 with an impressive 175 billion parameters. GPT-3 was a game-changer, providing a level of text understanding and generation that surpassed anything seen before. Its ability to generate human-like text and perform a variety of language tasks without specific tuning captured the public’s attention and imagination.
The Current State of the Art: GPT-4 Turbo and Claude 3 Opus
The most recent advancements came with the introduction of GPT-3.5 in December 2022 and GPT-4 in March 2023 (paper). GPT-4, with a reported 1.76 trillion parameters, employs a mixture of experts approach and multimodality, i.e. several models fine-tuned for specific tasks to optimize response accuracy. This version also introduced multimodality, further broadening the applications of LLMs in diverse fields.
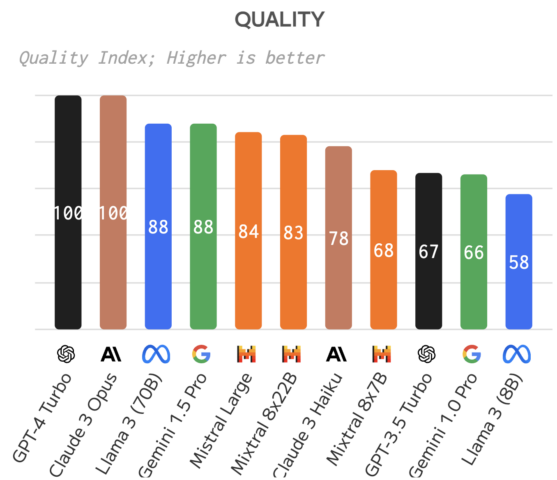
In the meantime, OpenAI has released a new version of GPT-4 called GPT-4 Turbo with new key features, such as a faster processing speed, a context window of up to 128,000 tokens (equiv. 300 pages of text) and a knowledge cutoff in April 2023. For comparison of GPT-4 Turbo to competing models and benchmark tests see here, here and here. At the moment, GPT-4 Turbo and Anthropic’s Claude 3 Opus stand out as the leading LLMs in terms of overall quality and performance. However, Meta’s Llama 3 (Meta), Google’s Gemini 1.4 Pro, and Mistral Large are closely following the two leading models.
HOW LLMs WORK
Large Language Models (LLMs) like ChatGPT function through a sophisticated series of steps that transform raw text into intelligent responses. Let’s dive into the three core stages of how LLMs process and generate text:
Step 1: Tokenization
The first step in the functioning of an LLM is tokenization. This process involves breaking down the input text into smaller pieces, known as tokens. Each token generally represents something between a syllable and a word, generally about three-fourths of a word. however, this can of course vary based on the word’s length and the model’s design. For example, shorter words like “high” might be a single token, whereas a longer word like “summarization” could be split into two or three tokens.
Tokenization methods differ among models. Some models might break down words by separating prefixes and suffixes, considering the contextual relevance of each segment. For instance, in the phrase “what is the tallest building,” a word like “tallest” might be tokenized different by different models, to emphasize the superlative suffix to enable understanding of grammatical variations.
Step 2: Embeddings
After tokenization, the next step is converting these tokens into embeddings. Embeddings are numerical representations that turn the textual tokens into a format the model can process—essentially, vectors of numbers. These vectors are stored in a structure known as an embedding vector database.
Each vector captures not just the token but also its relationship to other tokens, much like a multi-dimensional map of language where each word’s meaning is defined not just in isolation but in relation to others. This database is crucial for the model to assess and understand the nuances of language, such as context, synonyms, and semantic similarity.
Step 3: The Transformer Mechanism
The final and perhaps most revolutionary step involves the Transformer architecture, which uses what is known as the multi-head attention mechanism. This process helps the model determine which parts of the text are most important and how different words relate to each other within a sentence or a larger text block.
Transformers work by creating matrix representations from the embeddings. These matrices are then processed to generate a new matrix that predicts the next likely word in the sequence. This prediction is based on the “attention” each word receives, which is essentially a score that indicates how much focus the model should place on each word given its context.
The multi-head attention mechanism allows the model to consider multiple interpretations and relations simultaneously, giving it a dynamic and flexible way to understand and generate text. This ability to process and generate natural language on the fly is what makes LLMs particularly powerful for tasks like conversation, text completion, and even creative writing.
Training LLMs: Minimizing Prediction Error by Adjusting Parameters
Training an LLM is a data-intensive process. It starts with collecting a vast dataset from diverse sources such as books, websites, and other text-rich mediums. This data undergoes pre-processing to optimize it for training, the so called pre-training, which includes cleaning and transforming the data into a usable format.
The actual training involves adjusting the model’s parameters (weights) based on the input data to minimize errors in prediction. This adjustment happens through numerous iterations, where the model learns to predict text sequences more accurately. Post training, the model is evaluated on unseen data to ensure it generalizes well to new text.
FINE-TUNING: TAILORING AI TO SPECIFIC NEEDS
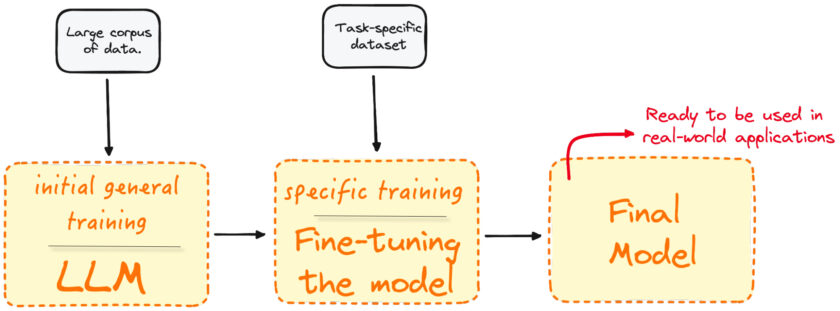
One of the most exciting aspects is the potential for fine-tuning a trained model. This process not only makes these powerful tools accessible but also highly adaptable to the specific context of real-world applications, such as personalised medicine, autonomous vehicles, spam detection, and so forth. Fine-tuning is where LLMs are customized to fit precise needs of users, businesses, academic institutions, or authorities.
The Basics of Fine-tuning
Initially, large language models like GPT, Claude, or Gemini are trained on vast datasets to develop a broad understanding of language. This foundational training equips them with general capabilities, which serve as a versatile starting point. However, the real magic happens during fine-tuning—a process that refines trained models to excel in particular tasks.
Consider a practical example: suppose a restaurant wants to automate taking orders through an AI system. By fine-tuning an LLM with data from actual conversations between customers and the restaurant, the model can learn specific jargon related to food and dishes, understand relevant questions, and respond appropriately. This tailored model becomes proficient in facilitating the entire order process, from inquiry to purchase.
Advantages of Fine-tuning
Fine-tuning has several key benefits that make it a preferred approach over training a model from scratch:
- Efficiency: Fine-tuning a pre-trained model is significantly faster than training a new model, as the foundational knowledge is already in place.
- Accuracy: Because the model is initially trained on a large and diverse dataset, it has a well-rounded understanding of language. Fine-tuning builds on this to create a model that performs with high precision in specific scenarios.
- Versatility: A single foundational model can be fine-tuned multiple times for various applications. Whether it’s customer service, medical consultations, or legal advice, the same base model can adapt to diverse needs.
- Data Quality Impact: The success of fine-tuning heavily relies on the quality of the dataset used. High-quality, relevant data leads to better performance, while poor-quality data can hinder the model’s effectiveness.
Fine-tuning in Action
In technical terms, fine-tuning is the process of adjusting parameters of a model that were learned during the training stage by a further, more specific training process, now on a specific, usually smaller, domain-specific dataset to enhance its performance for particular tasks or application. The domain-specific data set reflects the specific language and scenarios the model will encounter in its final application. For example, fine-tuning a model on customer service dialogues from a telecom company would involve exposing it to terminology, customer complaints, and typical service requests specific to the telecom industry. That said, fine-tuning LLMs is more than a technical process—it’s a gateway to making AI personal and practical for every conceivable application.
CHALLENGES OF LLMs
As the realm of artificial intelligence continues to expand, so too do the complexities and challenges associated with LLMs. Despite their significant advancements, these models still suffer from a range of limitations and ethical concerns that underscore the importance of reasonably balancing technological progress and its societal implications.
Limitations of Understanding and Reasoning
One of the most pronounced limitations of LLMs lies in their handling of tasks involving complex logic and reasoning. Unlike humans, who generally excel at integrating diverse cognitive skills to understand abstract concepts, LLMs often falter. Their struggles are particularly evident in areas like mathematics and formal logic, where precision and structured thinking are paramount. These models, for all their linguistic prowess, still cannot match the depth of human understanding in these fields.
Bias and Safety Concerns
Another critical challenge is the inherent bias found in the training data of LLMs. Since these models learn from vast swathes of internet data, they inevitably absorb the biases present in that information. Human biases, whether intentional or inadvertent, seep into the models, leading to outputs that can perpetuate these prejudices. This issue is compounded by the ongoing debate over the censorship and moderation of content generated by LLMs, raising questions about the balance between free expression and the responsibility to prevent harm.
Knowledge Acquisition and “Hallucinations”
Historically, LLMs could only operate within the scope of their training data, lacking the ability to update their knowledge in real time. Advancements, like the ability of some models to browse the web, have begun to address this limitation. However, these enhancements come with their own set of challenges, particularly the accuracy of the information retrieved and the model’s propensity for “hallucinations“—asserting incorrect information with confidence. Especially the legal sector seems vulnerable to hallucinations, as a recent study of Stanford University suggests, and as some US lawyers have painfully learnt by now. Such errors can undermine the reliability and trustworthiness of AI systems.
Computational and Environmental Costs
The environmental and computational costs of training and running LLMs are substantial. The advanced capabilities of models like GPT-3 and GPT-4 require immense processing power, which in turn demands significant energy consumption and hardware resources. This not only makes LLMs expensive to develop and maintain but also raises concerns about their environmental impact, considering the large carbon footprint associated with their energy use.
Ethical and Legal Implications
From an ethical standpoint, the use of LLMs is fraught with challenges. The potential for misuse in creating convincing fake content—be it text, images, or videos—, so called deep fakes, poses significant risks for misinformation and fraud. Moreover, the training of these models often involves the use of copyrighted material without explicit permission, leading to numerous legal battles and ethical questions about the propriety of such practices.
The Future of Work and AGI Concerns
Looking ahead, the disruption of the white-collar workforce by LLMs and other AI technologies may be inevitable. Fields such as law, journalism, and software development are particularly vulnerable to automation, which can perform tasks traditionally handled by professionals. Furthermore, as we inch closer to achieving artificial general intelligence (AGI), the need for ensuring that these systems align with human values and ethics becomes even more critical.
CONCLUSION
As we conclude this deep dive, it seems fair to say that LLMs like ChatGPT and Claudes offer enormous potential to streamline operations and decision-making but also present numerous technological and particularly societal challenges.
Advancements in accuracy, bias reduction, and data security are key for the future of LLMs. Ethical considerations around AI’s privacy implications and content reliability must be addressed before mass adoption is possible. The workforce, especially in cognitive fields like the legal sector will face significant changes and challenges to many highly educated and well payd professions. As regards the patent industry, however, this project, ALPHALECT.ai, aims at democatising IP protection by automating patent processes.
Your insights are crucial. How do you envision AI and LLMs shaping your industry? Share your thoughts below as we adapt to these developments and continue this transformative journey.
At ALPHALECT.ai, we explore the power of AI to revolutionize the European IP industry, building on decades of collective experience in the industry and following a clear vision for its future. For answers to common questions, explore our detailed FAQ. If you require personalized assistance or wish to learn more about how legal AI can benefit innovators, SMEs, legal practitioners, and innovation and the society as a whole, don’t hesitate to contact us at your convenience.
Pingback:An Introduction to Legal AI – ALPHALECT.ai
Pingback:AI’s Disruptive Impact on Patent Attorney’s Business Model – ALPHALECT.ai
Pingback:Confidentiality and Client Data Protection in the Age of Legal AI – ALPHALECT.ai
Pingback:Welcome to ALPHALECT.ai – Pioneering AI Solutions for the European IP Landscape – ALPHALECT.ai
Pingback:Legal AI: A Beginner’s Guide to Large-Scale Artificial Intelligence – Senior Tech Info